Time flies really fast. It’s been over a year ago since I first released the server code for Acoustid . Back then, Acoustid was just an experiment, but the project is becoming more and more visible and these days it’s serving between 500k and 600k lookups every day .
What makes me more happy than that the project is being useful is that the decisions I’ve made regarding the server architecture turned out to work very well and the server generally very fast and scalable. The average lookup processing time is around 60ms and I expect the number to go down, not up in the future.
As the post about Chromaprint says, the audio fingerprints used in Acoustid are basically vectors of numbers. For performance reasons on the client side, applications are now calculating these fingerprints only from the first two minutes of audio files. That means that when the server scores the results, it only considers the first two minutes of audio. If two tracks have the same intro that is over two minutes long and then they get different, Acoustid will unfortunately see them as the same. This doesn’t cause too many practical problems though. The MusicDNS service that MusicBrainz currently supports also use only the first two minutes.
Before scoring the results, the server must somehow get the results in the first place, and this is where normally things get slow. The database currently has more than 10M fingerprints. If we assume all fingerprints have at least two minutes (which means 948 numbers per fingerprint), that’s 9480M numbers to search in. Just saving these numbers on disk, together with the pointers to the fingerprints they come from, would require 76GB of space. And since the search must be fast, the data must fit in RAM. This is obviously not the way to go if we want to be able to host the service on a single server and yet get response times below 100ms. The search space must be reduced.
Because Acoustid is meant to be used for file identification, I don’t necessarily need to search anywhere in the fingerprint. I know that the fingerprints I get are from the start of the song, I know that if the two fingerprints are similar enough, they must match across the whole length and I can assume that they also must match a specific (smaller) part. So even though the original fingerprints are two minutes long, I decided to search only in the part between 0:10 and 0:25.
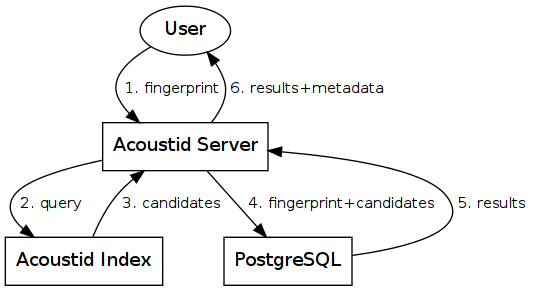
The sub-fingerprints that cover these 15 seconds are stored in the Acoustid index database. Whenever I search for a fingerprint, I extract the 15 seconds long sub-fingerprint (“query”) and send it to the index server. The server returns a list of matching fingerprint IDs (“candidates”). These candidates represents fingerprints that might match the original fingerprint, but to not necessarily have to, because all I know about them is that they matched the extracted 15 seconds long query.
The next step is to take these candidates and compare them against the original fingerprint. This is done in PostgreSQL, where the full fingerprints are stored. Each of the candidates is compared against the original fingerprint using a function that tries to align the two fingerprints and then calculates the bit-error-rate between the overlapping parts. The result of this function is a score between 0 and 1. Fingerprints with the score above a certain threshold are considered valid matches, MusicBrainz metadata is looked up for them, they are returned to the user and that’s the end of it.
The whole process looks something like this:
This covers the searching side of the server. I’ll try to write another post soon about the data management side (importing, merging, etc).